
Suicide and suicide attempts are very, very difficult to predict. It is the end result of the complex interaction between social, psychological and biological factors. Statistically speaking, it is also relatively rare, making prediction even more difficult.
In their already seminal paper on 50 years of research into risk factors for suicidal thoughts and behaviours, Franklin et al showed that our ability to predict a suicide attempt is hardly better than chance. In other words, one might as well flip a coin. Moreover, the authors stress that prediction has not improved substantially after decades of research.
Against this backdrop, machine-learning based risk-algorithms have been put forward as an important tool to improve prediction. According to Wikipedia, “Machine learning (…) uses statistical techniques (…) to “learn” (e.g. progressively improve performance on a specific task) from data, without being explicitly programmed”. Machine learning can deal with (big) data sets with large numbers of records and many different variables and is mainly data driven. It is used to make cars drive autonomously, to help Netflix predict what its customers will watch, but it can also help clinicians such as radiologists make better clinical decisions.
Machine learning has been put forward as a way of improving our prediction of suicide attempts. Indeed, in a novel paper, Walsh, Ribeiro and Franklin applied machine learning algorithms to longitudinal clinical data to predict suicide attempts in adolescents.

Machine learning has been put forward as a way of improving our prediction of suicide attempts.
Methods
In the paper, the authors applied a powerful and flexible machine learning algorithm called random forest to longitudinal clinical data. The data were collected from inpatients and outpatients who visited the Vanderbilt Medical University from 1998 until 2015. This was done as part of a much larger initiative to develop a DNA biobank.
In this dataset collected over an 18 year period, 2,247 adolescents with a registration for self-harm were identified. As not all self-injury codes in the dataset refer to an actual suicide attempt, two experts rated each candidate record. After this expert review, 974 cases had a confirmed record of at least one suicide attempt.
Controls were three different groups: 496 with other self-injury, 7,059 with depressive symptoms and 25,081 general hospital controls.
Predictors were derived from the electronic health records and included: diagnostics, medication, comorbidities, social economic factors and so on.
Random forests were used to evaluate the models to predict suicide attempts at different time points (from 1 week to 2 years).
Results
- It was possible to predict suicide attempts when compared with the control groups
- Standard performance metrics such as area under the curve were good across all time windows
- The model performed better if:
- the timeframe to the suicide attempt was shorter
- the control group was less at risk
- Random forest did significantly better than models using standard logistic regression analyses.
The authors suggest that: “machine learning on longitudinal clinical data may provide a scalable approach to broaden screening for risk of nonfatal suicide attempts in adolescents.”
Conclusions
The application of machine learning to electronic health records made it possible to accurately determine which patient was a case (i.e., attempted suicide) in the dataset and which was a control. Prediction got better when the attempt was more imminent and when the control group was healthier.
Strengths and limitations
The major strength of the paper is that they apply novel algorithms to a rich set of routinely available data. The growth of routinely available data, and the development of stronger algorithms provides opportunities for exploration, hypothesis generation and prediction.
There is a risk, however, that we have unrealistic expectations about the types of problems that we can solve with machine learning. One of the main challenges in predicting suicide attempts is that suicide attempts are very rare. Any test can have a good sensitivity and specificity, but if the prevalence in the testing population is low (such as in general population, primary care or in a general hospital setting), a positive result on a test still does not tell us if a person is ill. In other words, when the prevalence of an event is low, tests are more often wrong than right. This is called Bayes’ rule.
Given that over a period of 18 years of data collection, the authors reported 974 cases of suicide attempts, the prevalence of adolescents who present following a suicide attempt at the Vanderbilt University Medical Center appears to be quite low. Even if we set prevalence at 1% and the specificity and the sensitivity at 0.9, the likelihood that an adolescent with a ‘positive test’ actually being a case (i.e., suicide attempt) is only 8%. No machine learning technique can solve that conundrum.
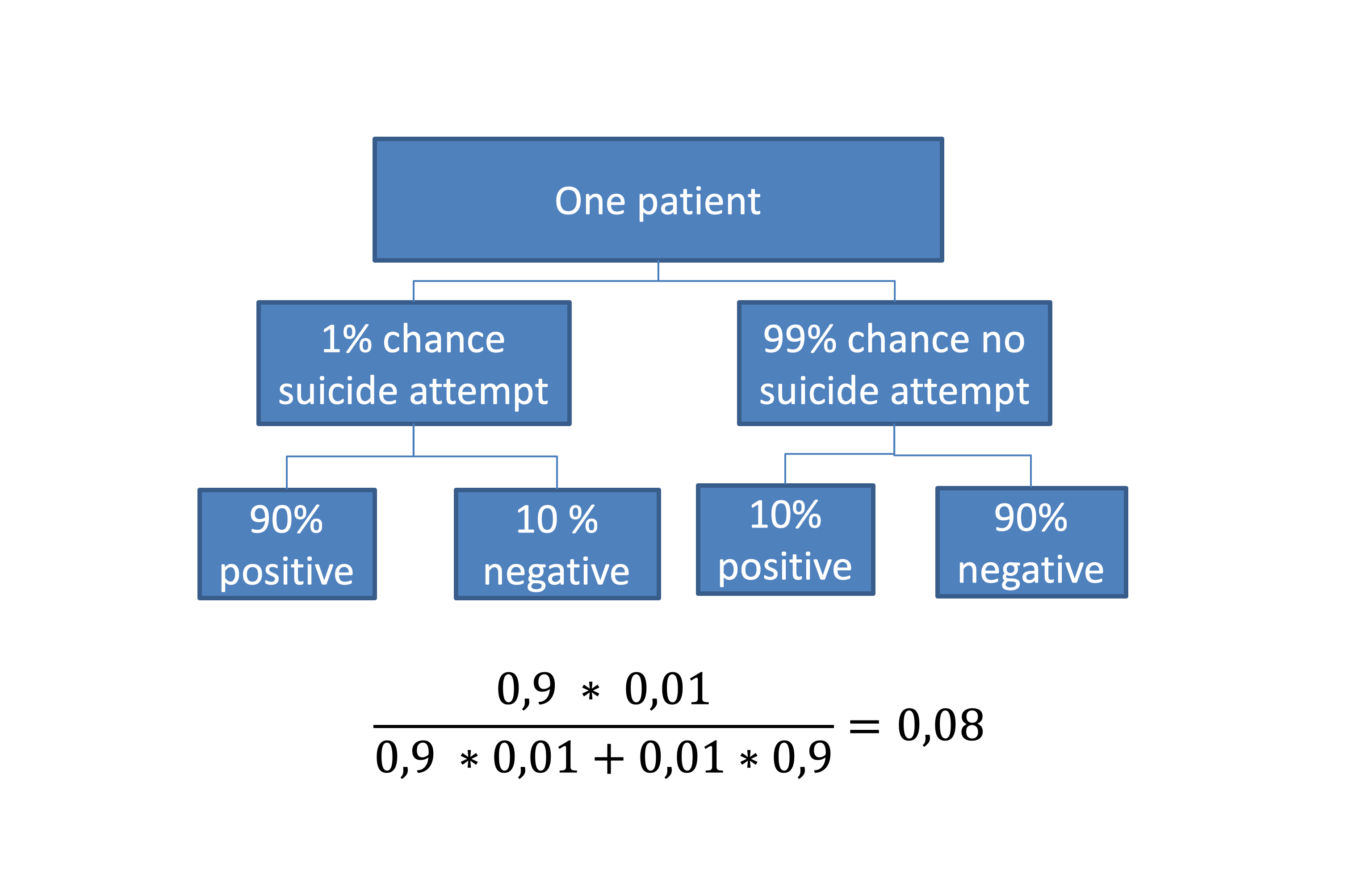
The chance of a suicide attempt after a positive test following Bayes’ rule.
With regard to the application of machine learning in medical settings, the data used in this study were collected as part of an intense longitudinal research project. Most hospitals and mental health institutions do not have such a high-quality data infrastructure, making prediction even more difficult. Privacy issues are also an important aspect that need attention before algorithm-based suicide prediction can be implemented at a large scale, at least in Europe.
I would argue that the machine learning approach of model building and validation offers hope for suicide prevention. This approach includes multiple checks to see whether a statistical model actually fits the data via techniques such as cross-validation and bootstrapping. This makes the results more robust and reproducible. Relatedly, in my view, an important reason for the relative slow progress in the prediction of suicidal behaviour does not lie in the wrong application of statistics per se, but rather in the omission of an unambiguous scientific theory to explain suicidal behaviour. Without theory, we are basically searching in the dark. Contemporary theories of suicidal behaviour have been put forward in the past decade and are currently being validated. If we can apply machine learning approaches to theory validation and also adopt the open science recommendations of study preregistration, the provision of reproducible codes and open data we can really advance the field of suicide prevention.

Even if we set prevalence at 1% and the specificity and the sensitivity at 0.9, the likelihood that an adolescent with a ‘positive test’ actually being a case (i.e., suicide attempt) is only 8%. No machine learning technique can solve that conundrum.
Implications for practice
- Machine learning has the potential to greatly improve our prediction of suicidal behaviour.
- However, given the low prevalence of suicidal behaviour, prediction will always be challenging.
- It’s unrealistic to think that an algorithm will solve this problem in the short run.
- To really advance the field of suicide prevention, machine learning should be combined with theory and novel data collected consistent with the open science framework.

Machine learning has the potential to greatly improve our prediction of suicidal behaviour. However, given the low prevalence of suicidal behaviour, prediction will always be challenging.
Conflicts of interest
None
Links
Primary paper
Walsh CG, Ribeiro JD, Franklin JC. (2018) Predicting suicide attempts in adolescents with longitudinal clinical data and machine learning. J Child Psychol Psychiatr. . doi:10.1111/jcpp.12916
Other references
Franklin, Joseph C., et al. “Risk factors for suicidal thoughts and behaviors: A meta-analysis of 50 years of research.” Psychological Bulletin 143.2 (2017): 187.
de Beurs, Derek. “Network analysis: a novel approach to understand suicidal behaviour.” International journal of environmental research and public health 14.3 (2017): 219.
O’Connor, Rory C., and Matthew K. Nock. “The psychology of suicidal behaviour.” The Lancet Psychiatry 1.1 (2014): 73-85.
Wagenmakers, Eric-Jan, et al. “Bayesian inference for psychology. Part I: Theoretical advantages and practical ramifications.” Psychonomic bulletin & review 25.1 (2018): 35-57.
https://en.wikipedia.org/wiki/Bayes%27_theorem
https://en.wikipedia.org/wiki/Machine_learning
Photo credits
- Photo by Rui Silvestre on Unsplash
- Photo by Markus Spiske on Unsplash
- Photo by rawpixel on Unsplash
- Photo by Ash Edmonds on Unsplash

Thank you, very interesting. The predictions being better in the short term is not surprising – just like weather prediction over a short period is pretty good even without equipment.
Many of the factors involved in suicide will not be captured even in state of the art records simply because they are unknown or impractical to measure. The contents of patient records are only snapshots of people at best and really reflect what others i.e clinicians like myself observe and interpret. Until the technology exists to real time monitor neurophysiological correlates of behaviour (and thoughts for that matter) in the same way we can monitor heart rate note, that is the best we have.
Little late with this but the bayes equation in the second image is incorrect. The Denominator should be “.9*.01+.1*.99” rather than “.9*.01 + .9*.01” The math shown produces a value of .5 rather than .08 as it should.